source:Tianshou–强化学习算法框架学习笔记 - 知乎 (zhihu.com)
Cheat Sheet — Tianshou 0.5.1 documentation
欢迎查看天授平台中文文档 — 天授 0.4.6.post1 文档 (tianshou.readthedocs.io)
一、Tianshou的基本框架
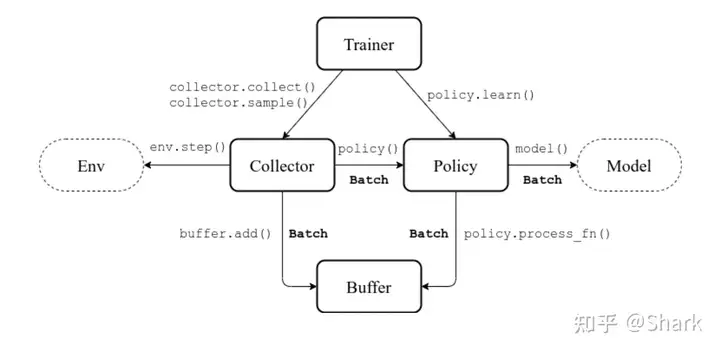
天授(Tianshou)把一个RL训练流程划分成了几个子模块:trainer(负责训练逻辑)、collector(负责数据采集)、policy(负责训练策略)和 buffer(负责数据存储),此外还有两个外围的模块,一个是env,一个是model(policy负责RL算法实现比如loss function的计算,model就只是个正常的神经网络)。下图描述了这些模块的依赖:
例子:
1 | import gymnasium as gym |
下面,我们就将一步一步的了解上图中所有的API,对Tianshou有一个大致的了解。
二、Batch
下面我们首先来看看Batch这个数据结构:
1 | import numpy as np |
可以发现,batch类似于dict,存储key-value对,并且可以自动将value转化成numpy array。
下面例子演示Batch存储numpy和pytorch的数据:
1 | import torch |
将Batch中的数据类型统一转换成numpy或pytorch的数据类型:
1 | batch_cat.to_numpy() |
三、ReplayBuffer
Replay buffer在RL的off-policy中非常常用,其可以存储过去的经验,以便训练我们的agent。
在Tianshou中,可以把replay buffer看成一种特殊的Batch。
下面是使用replay buffer的例子:
1 | from tianshou.data import Batch, ReplayBuffer |
replay buffer中保留了七个属性,Tianshou推荐我们使用这七个推荐的属性,而不是自己去创建其他属性。

我们也看到了,buffer其实就是一种特殊的Batch,那他存在的意义是什么呢?
就在于可以从buffer中sample数据给到collector中,供agent进行训练。
现在Tianshou支持gymnasium,所以又多了两个属性:truncated和terminated。
我们还可以高效的从buffer中追踪trajectory信息。
下面这段代码可以获得下标为6的step所处的episode的第一个step的下标
1 | # Search for the previous index of index "6" |
同理,下面代码可以返回在当前episode中下一个step的下标:
1 | # next step of indexes [4,5,6,7,8,9] are: |
这在n-step-return的时候非常有用(n-step TD)
四、Vectorized Environment
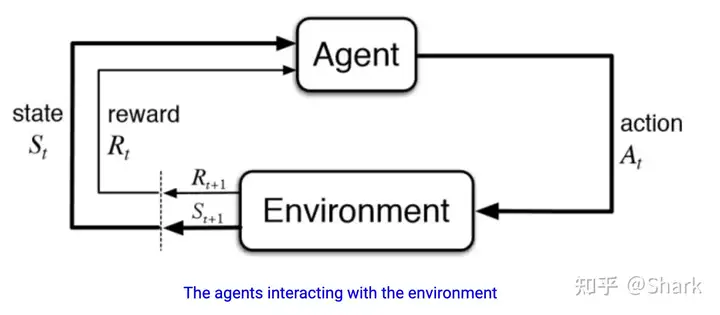
在gym中,环境接收一个动作,返回下一个状态的观测和奖励。这个过程很慢,并且常常是实验的性能瓶颈,所以Tianshou利用并行环境加速这一过程。
1 | from tianshou.env import SubprocVectorEnv |
下面是单个环境与多个环境的对比:
1 | from tianshou.env import DummyVectorEnv |
五、Policy
Policy就是agent如何做出action的\pi函数。
所有Policy模块都继承自BasePolicy类,并且具有相同的接口。
下面我们就来看看如何实现一个简单的REINFORCE的policy。
1 | from typing import Any, Dict, List, Optional, Type, Union |
policy最重要的两个功能就是
- 选择动作(forward)
- 更新参数(update),update先调用process_fn函数,处理从buffer来的数据;然后调用learn,反向传播,更新参数。
1 | from typing import Any, Dict, List, Optional, Type, Union |
六、Collector
collector与policy和环境交互,在其内部,把envs和buffer有机的结合起来,封装了其中的数据交互。
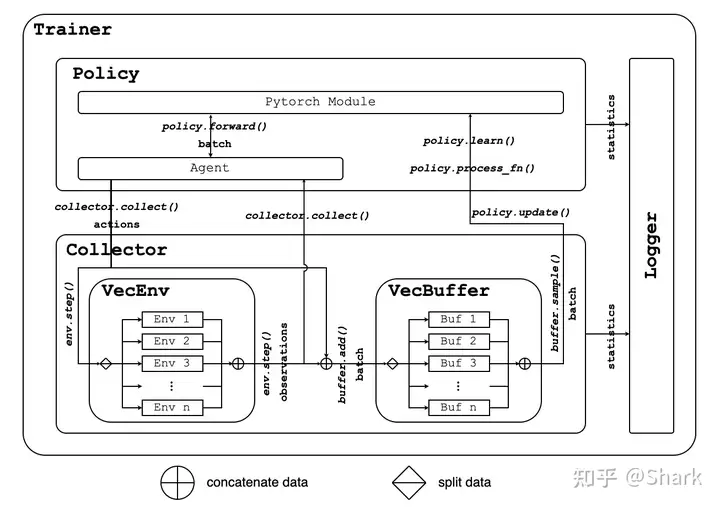
Collector在训练(收集数据)时和评估策略时都可以使用。
Data Collecting:
1 | from tianshou.data import VectorReplayBuffer |
Policy evaluation:
我们已经有了一个policy,现在我们想评估一下这个policy,看看reward情况等等。
1 | import gym |
七、Trainer
Trainer是Tianshou中的顶层封装,它控制traning loop和对Policy的evaluation。Trainer控制Policy和Collector的交互。
Tianshou中包含三类Trainer:On-policy training, off-policy training, offline training.
下面是REINFORCE算法的整体流程(利用On-policy)。
1 | import gymnasium as gym |
可以发现,trainer就是包装了一下循环。
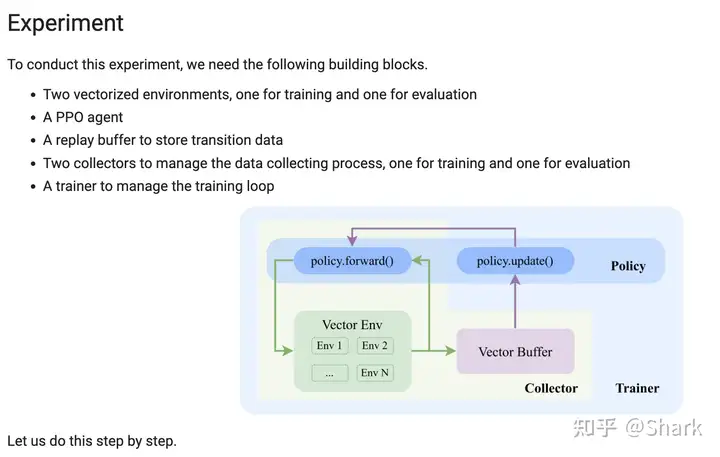
八、Experiment
这一节我们用PPO来解决CartPole
1 | import gym |